Prompt Category Classification (Part 1)

In the quest to enhance the quality and user experience of language models, prompt classification plays a vital role. To address this challenge, pulze.ai conducted an experiment to evaluate different approaches for classifying prompts given to Language Models (LLMs) into distinct categories. Our goal was to identify a robust and effective prompt classification setup that could contribute to improving the overall performance of LLMs.
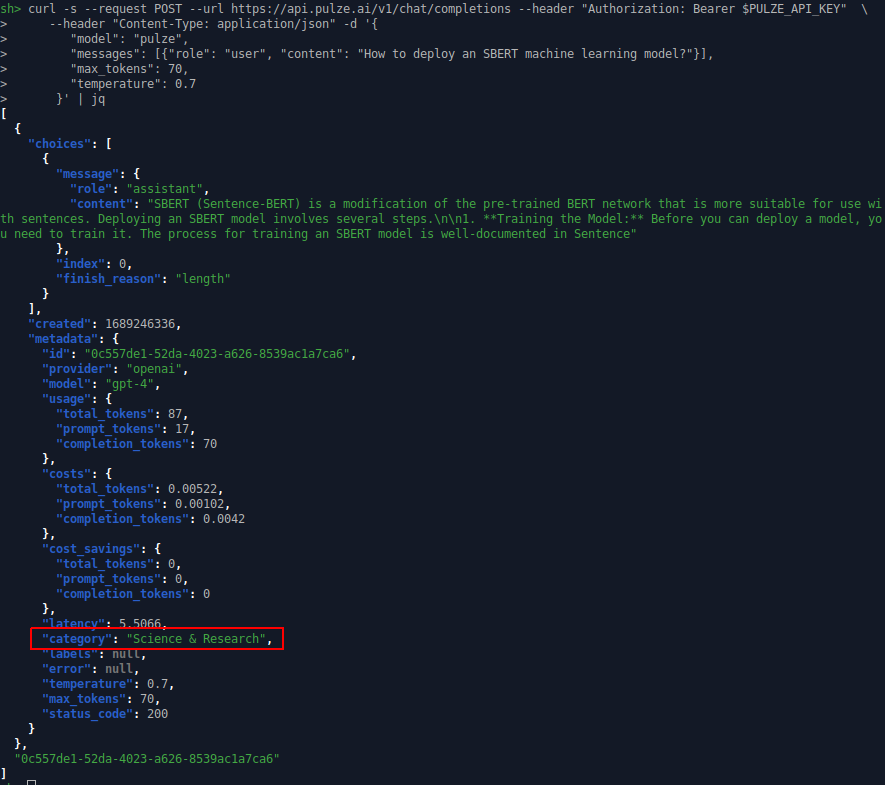
The outcome of the study outlined in this blog post has been integrated in our pulze.ai API. It is not only improving the selection of the most suitable model, but we are also providing the categorization back to the user to gain further insights about their prompts.
For this experiment, we generated a dataset using GPT-4; however, it is important to note that the diversity of this dataset may not fully resemble a real-world dataset. Additionally, annotating real-world datasets can be costly. Hence, we also evaluated the performance of the prompt classification approaches under few-shot learning conditions.
This blog post highlights the four scenarios we explored and their corresponding evaluation results.
- Classical TF-IDF n-gram SVC: Inspired by the research paper titled "A Comparison of SVM against Pre-trained Language Models (PLMs) for Text Classification Tasks" (https://arxiv.org/pdf/2211.02563), we implemented a classical approach using Term Frequency-Inverse Document Frequency (TF-IDF) with Support Vector Classification (SVM) and Logistic Regression (LG) . This scenario served as our baseline for comparison and provided insights into the performance of traditional methods for prompt classification.
- Masked Language Modeling-Based Sequence Classification (BERT & others): The second approach we evaluated involved leveraging masked language models such as BERT (https://arxiv.org/pdf/1810.04805) and its variants. By fine-tuning these models for sequence classification, we aimed to harness the power of contextualized word representations to classify prompts effectively. We assessed the performance of BERT and similar models in this scenario (FT).
- Pretrained Sentence BERT-Based Sentence Embeddings + LR/SVC without CL Tuning: In this scenario, we explored the utilization of Sentence BERT (SBERT) (https://arxiv.org/pdf/1908.10084) for generating sentence embeddings. We combined SBERT's embeddings with simple linear models such as Logistic Regression (LR) or Support Vector Classification (SVC) for prompt classification. This setup allowed us to evaluate the effectiveness of sentence-level representations in improving the categorization of prompts without any Contrastive Learning (CL) tuning.
- SetFit-Based End-to-End Training of Sentence Embeddings with CL and Classification Head FT: Our final scenario involved employing the SetFit (https://arxiv.org/pdf/2209.11055) framework for prompt classification. SetFit facilitates end-to-end training of sentence embeddings by leveraging Contrastive Learning (CL) and fine-tuning the classification head. By integrating CL into the training pipeline, we aimed to enhance the discriminative power of sentence embeddings for prompt classification.
Experimental Evaluation:
Throughout the experiment, we assessed the performance of each scenario by F1 score. The evaluation was conducted on a diverse, class-balanced test dataset of prompts to ensure comprehensive results. We compared the effectiveness of each approach to determine their suitability for prompt classification in LLMs and addressed the limitations of few training data per category by evaluating a few-shot training scenario.
Results and Discussion:
In the full dataset experiment, we observed interesting results across different prompt classification approaches. Firstly, the classical combination of Support Vector Classification (SVC) and TF-IDF yielded surprisingly strong performance, achieving an accuracy of 94.1%. This traditional approach, known for its computational efficiency, showcased its effectiveness in prompt classification. However, considering the expected diversity of vocabulary in real-world settings, we suspect that this approach may not generalize well.
On the other hand, leveraging pretrained sentence embeddings with classifiers proved to be highly effective. The SBERT paraphrase-mpnet-base-v2 + SVC approach stood out with an impressive accuracy of 98.5% and demonstrated the potential of utilizing contextualized word representations pretrained for sentence similarity for prompt classification. This approach strikes a good balance between generalizability and computational efficiency.
The SetFit-based approaches, which involved end-to-end training of sentence embeddings with Contrastive Learning (CL) and fine-tuning the classification head, showed promising results, as well. While not quite reaching the performance of pretrained SBERT, they came close. However, it's important to note that a larger-scale hyperparameter study was not conducted in this experiment. We expect that with further optimization, the SetFit approaches could compete on par with pretrained SBERT. Nevertheless, it's worth considering that the SetFit approaches involve contrastive learning and fine-tuning, making them less computationally efficient compared to the pretrained SBERT models.
Both the SBERT models and the SetFit approaches exhibited high F1 scores even with limited labeled examples per class, i.e. in the few-shot learning scenario. This suggests that these methods are capable of integrating other categories and perspectives on prompts without requiring a large training set of annotated examples. This is a significant finding, as it indicates the potential for prompt classification to incorporate diverse perspectives and adapt to different prompt categories even with limited available labeled data.
As anticipated, fine-tuned Masked Language Models (MLMs) such as BERT performed well for sequence classification. However, it's interesting to note that the performance varied across different models. In comparison to all other models (including SVC and LG!), the fine-tuned MLM models showed lower suitability for few-shot learning, as indicated by their lower F1 scores.
Conclusion
Overall, the results suggest that leveraging pretrained SBERT-based sentence embeddings with SVC provides a strong and efficient solution for prompt classification in real-world settings. The classical combination of SVC and TF-IDF, while surprisingly effective, may face challenges in handling diverse vocabularies. The SetFit approaches show promise but require further optimization, and fine-tuned MLM models perform well for sequence classification but may not be as suitable for few-shot learning tasks.
It's important to note that these observations were made using a generated dataset with GPT-4, which may not fully capture the complexity and diversity of real-world data. Further research including hyper-parameter studies and evaluation on diverse real-world datasets are needed to validate the generalizability and effectiveness of these approaches.
The findings of this study have been successfully implemented in the pulze.ai engine and return the prompt categorization transparently to the user.
In the next post of this series, we will focus how to deploy these models in a production environment.
